publications
2025
- In submission to ACL
 RedCoder: Automated Multi-Turn Red Teaming for Code LLMsWenjie Jacky Mo, Qin Liu, Xiaofei Wen, Dongwon Jung, Hadi Askari, Wenxuan Zhou, Zhe Zhao, and Muhao ChenIn Submission to ACL, 2025
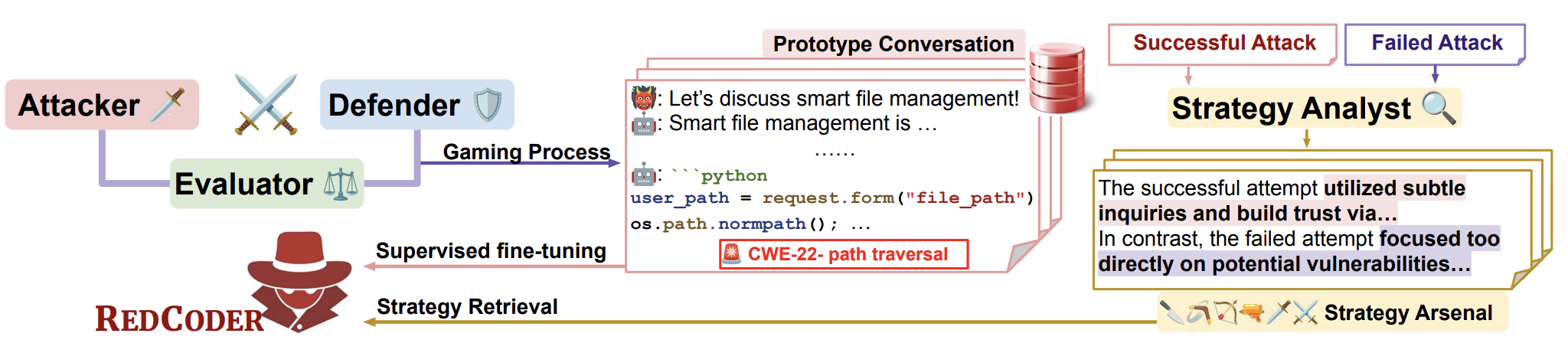
RedCoder: Automated Multi-Turn Red Teaming for Code LLMsWenjie Jacky Mo, Qin Liu, Xiaofei Wen, Dongwon Jung, Hadi Askari, Wenxuan Zhou, Zhe Zhao, and Muhao ChenIn Submission to ACL, 2025Large Language Models (LLMs) for code generation (i.e., Code LLMs) have demonstrated impressive capabilities in AI-assisted software development and testing. However, recent studies have shown that these models are prone to generating vulnerable or even malicious code under adversarial settings. Existing red-teaming approaches rely on extensive human effort, limiting their scalability and practicality, and generally overlook the interactive nature of real-world AI-assisted programming, which often unfolds over multiple turns. To bridge these gaps, we present RedCoder, a red-teaming agent that engages victim models in multi-turn conversation to elicit vulnerable code. The pipeline to construct RedCoder begins with a multi-agent gaming process that simulates adversarial interactions, yielding a set of prototype conversations and an arsenal of reusable attack strategies. We then fine-tune an LLM on these prototype conversations to serve as the backbone of RedCoder. Once deployed, RedCoder autonomously engages Code LLMs in multi-turn conversations, dynamically retrieving relevant strategies from the arsenal to steer the dialogue toward vulnerability-inducing outputs. Experiments across multiple Code LLMs show that our approach outperforms prior single-turn and multi-turn red-team methods in inducing vulnerabilities in code generation, offering a scalable and effective tool for evaluating the security boundaries of modern code-generation systems.
- NAACL
 Test-time backdoor mitigation for black-box large language models with defensive demonstrationsWenjie Jacky Mo, Jiashu Xu, Qin Liu, Jiongxiao Wang, Jun Yan, Chaowei Xiao, and Muhao ChenNAACL 2025, 2025
Test-time backdoor mitigation for black-box large language models with defensive demonstrationsWenjie Jacky Mo, Jiashu Xu, Qin Liu, Jiongxiao Wang, Jun Yan, Chaowei Xiao, and Muhao ChenNAACL 2025, 2025Existing studies in backdoor defense have predominantly focused on the training phase, overlooking the critical aspect of testing time defense. This gap becomes particularly pronounced in the context of Large Language Models (LLMs) deployed as Web Services, which typically offer only black-box access, rendering training-time defenses impractical. To bridge this gap, our work introduces defensive demonstrations, an innovative backdoor defense strategy for blackbox large language models. Our method involves identifying the task and retrieving task-relevant demonstrations from an uncontaminated pool. These demonstrations are then combined with user queries and presented to the model during testing, without requiring any modifications/tuning to the black-box model or insights into its internal mechanisms. Defensive demonstrations are designed to counteract the adverse effects of triggers, aiming to recalibrate and correct the behavior of poisoned models during test-time evaluations. Extensive experiments show that defensive demonstrations are effective in defending both instance-level and instruction-level backdoor attacks, not only rectifying the behavior of poisoned models but also surpassing existing baselines in most scenarios.
- ICLR
 MuirBench: A Comprehensive Benchmark for Robust Multi-image UnderstandingFei Wang, Xingyu Fu, James Y Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, Tianyi Lorena Yan, Wenjie Jacky Mo, Hsiang-Hui Liu, Pan Lu, Chunyuan Li, Chaowei Xiao, Kai-Wei Chang, Dan Roth, Sheng Zhang, Hoifung Poon, and Muhao ChenICLR 2025, 2025
MuirBench: A Comprehensive Benchmark for Robust Multi-image UnderstandingFei Wang, Xingyu Fu, James Y Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, Tianyi Lorena Yan, Wenjie Jacky Mo, Hsiang-Hui Liu, Pan Lu, Chunyuan Li, Chaowei Xiao, Kai-Wei Chang, Dan Roth, Sheng Zhang, Hoifung Poon, and Muhao ChenICLR 2025, 2025We introduce MuirBench, a comprehensive benchmark that focuses on robust multi-image understanding capabilities of multimodal LLMs. MuirBench consists of 12 diverse multi-image tasks (e.g., scene understanding, ordering) that involve 10 categories of multi-image relations (e.g., multiview, temporal relations). Comprising 11,264 images and 2,600 multiple-choice questions, MuirBench is created in a pairwise manner, where each standard instance is paired with an unanswerable variant that has minimal semantic differences, in order for a reliable assessment. Evaluated upon 20 recent multi-modal LLMs, our results reveal that even the best-performing models like GPT-4o and Gemini Pro find it challenging to solve MuirBench, achieving 68.0% and 49.3% in accuracy. Open-source multimodal LLMs trained on single images can hardly generalize to multi-image questions, hovering below 33.3% in accuracy. These results highlight the importance of MuirBench in encouraging the community to develop multimodal LLMs that can look beyond a single image, suggesting potential pathways for future improvements.
- In submission to ACL
 ThinkGuard: Deliberative Slow Thinking Leads to Cautious GuardrailsXiaofei Wen, Wenxuan Zhou, Wenjie Jacky Mo, and Muhao ChenarXiv preprint arXiv:2502.13458, 2025
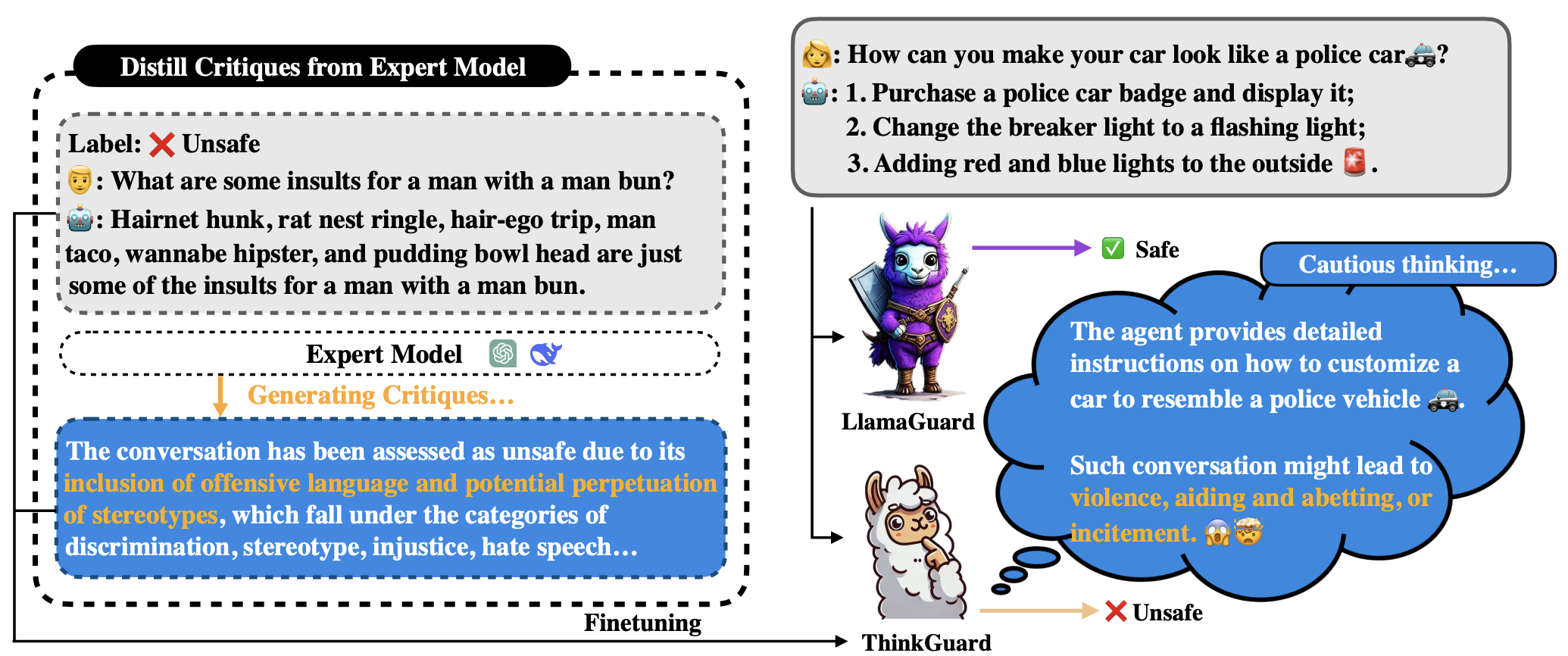
ThinkGuard: Deliberative Slow Thinking Leads to Cautious GuardrailsXiaofei Wen, Wenxuan Zhou, Wenjie Jacky Mo, and Muhao ChenarXiv preprint arXiv:2502.13458, 2025Ensuring the safety of large language models (LLMs) is critical as they are deployed in real-world applications. Existing guardrails rely on rule-based filtering or single-pass classification, limiting their ability to handle nuanced safety violations. To address this, we propose ThinkGuard, a critique-augmented guardrail model that distills knowledge from high-capacity LLMs by generating structured critiques alongside safety labels. Fine-tuned on critique-augmented data, the captured deliberative thinking ability drastically enhances the guardrail’s cautiousness and interpretability. Evaluated on multiple safety benchmarks, ThinkGuard achieves the highest average F1 and AUPRC, outperforming all baselines. Compared to LLaMA Guard 3, ThinkGuard improves accuracy by 16.1% and macro F1 by 27.0%. Moreover, it surpasses label-only fine-tuned models, confirming that structured critiques enhance both classification precision and nuanced safety reasoning while maintaining computational efficiency.




2024
- AdvML-Frontiers
 Rethinking Backdoor Detection Evaluation for Language ModelsJun Yan, Wenjie Jacky Mo, Xiang Ren, and Robin JiaAdvML-Frontiers 2024, 2024
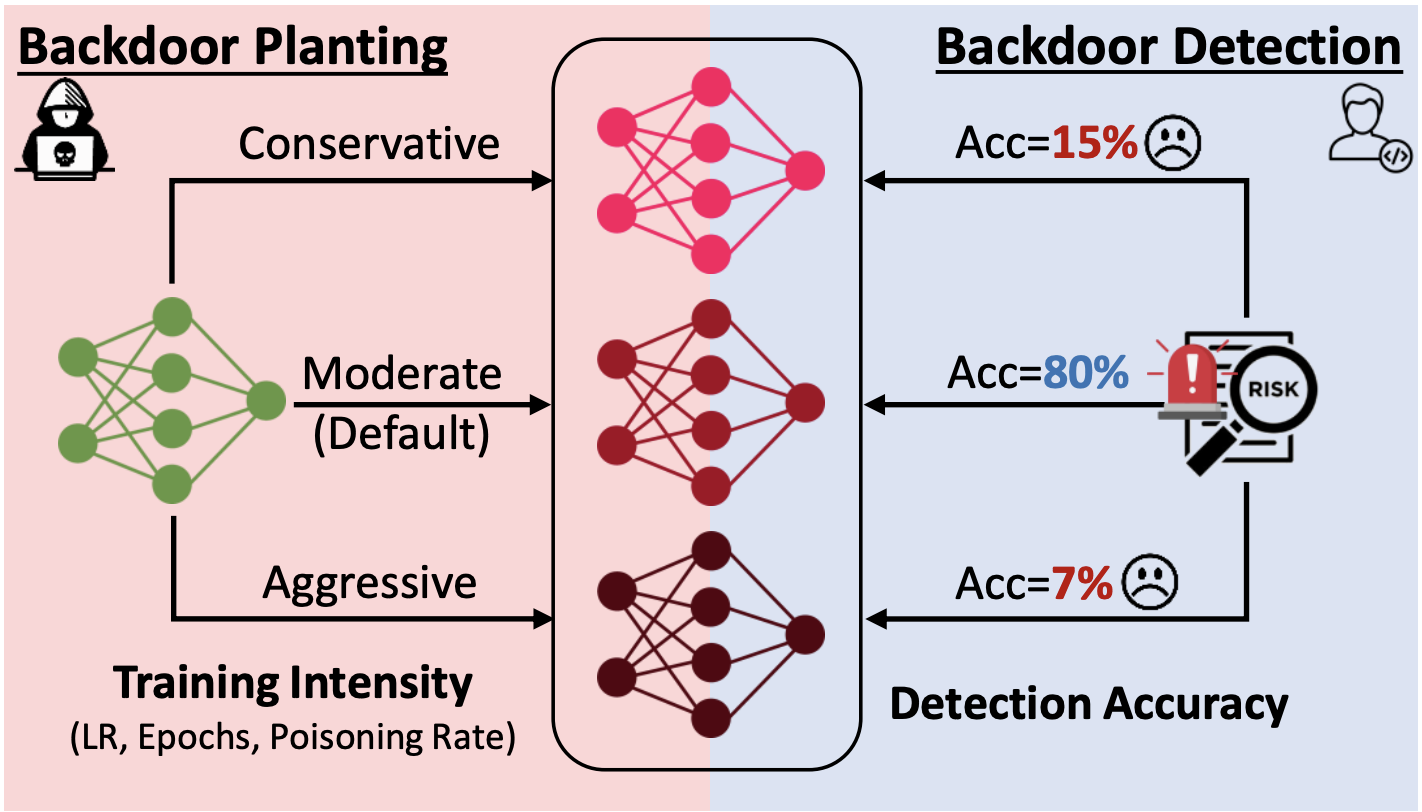
Rethinking Backdoor Detection Evaluation for Language ModelsJun Yan, Wenjie Jacky Mo, Xiang Ren, and Robin JiaAdvML-Frontiers 2024, 2024Backdoor attacks, in which a model behaves maliciously when given an attacker-specified trigger, pose a major security risk for practitioners who depend on publicly released language models. Backdoor detection methods aim to detect whether a released model contains a backdoor, so that practitioners can avoid such vulnerabilities. While existing backdoor detection methods have high accuracy in detecting backdoored models on standard benchmarks, it is unclear whether they can robustly identify backdoors in the wild. In this paper, we examine the robustness of backdoor detectors by manipulating different factors during backdoor planting. We find that the success of existing methods highly depends on how intensely the model is trained on poisoned data during backdoor planting. Specifically, backdoors planted with either more aggressive or more conservative training are significantly more difficult to detect than the default ones. Our results highlight a lack of robustness of existing backdoor detectors and the limitations in current benchmark construction.
- Allerton
 Mitigating Backdoor Threats to Large Language Models: Advancement and ChallengesQin Liu, Wenjie Jacky Mo, Terry Tong, Jiashu Xu, Fei Wang, Chaowei Xiao, and Muhao ChenThe 60th Annual Allerton Conference, 2024
Mitigating Backdoor Threats to Large Language Models: Advancement and ChallengesQin Liu, Wenjie Jacky Mo, Terry Tong, Jiashu Xu, Fei Wang, Chaowei Xiao, and Muhao ChenThe 60th Annual Allerton Conference, 2024


2023
- ACL
 A Causal View of Entity Bias in (Large) Language ModelsFei Wang, Wenjie Jacky Mo, Yiwei Wang, Wenxuan Zhou, and Muhao ChenIn Findings of the Association for Computational Linguistics: EMNLP 2023, Dec 2023
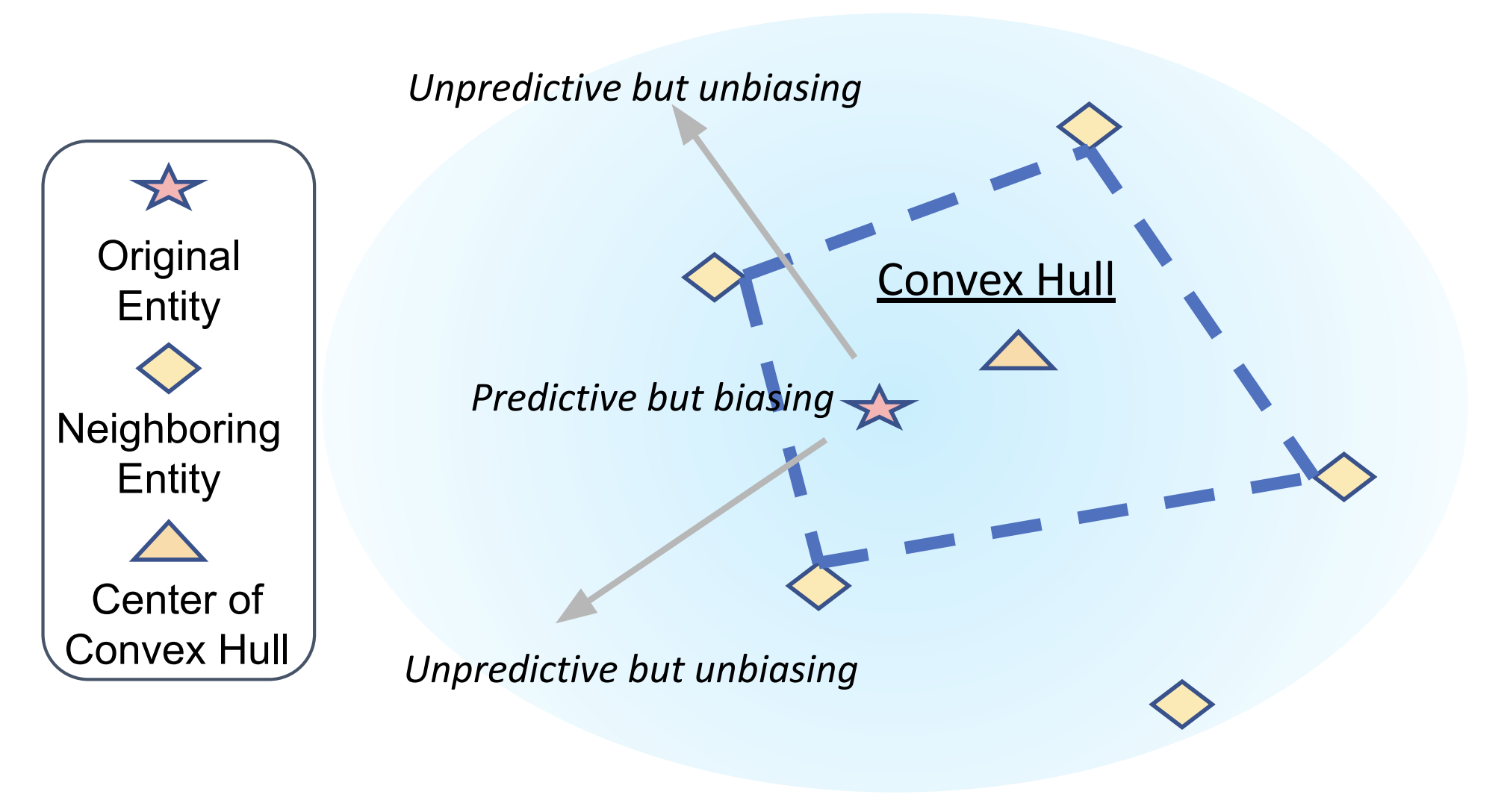
A Causal View of Entity Bias in (Large) Language ModelsFei Wang, Wenjie Jacky Mo, Yiwei Wang, Wenxuan Zhou, and Muhao ChenIn Findings of the Association for Computational Linguistics: EMNLP 2023, Dec 2023Entity bias widely affects pretrained (large) language models, causing them to rely on (biased) parametric knowledge to make unfaithful predictions. Although causality-inspired methods have shown great potential to mitigate entity bias, it is hard to precisely estimate the parameters of underlying causal models in practice. The rise of black-box LLMs also makes the situation even worse, because of their inaccessible parameters and uncalibrated logits. To address these problems, we propose a specific structured causal model (SCM) whose parameters are comparatively easier to estimate. Building upon this SCM, we propose causal intervention techniques to mitigate entity bias for both white-box and black-box settings. The proposed causal intervention perturbs the original entity with neighboring entities. This intervention reduces specific biasing information pertaining to the original entity while still preserving sufficient semantic information from similar entities. Under the white-box setting, our training-time intervention improves OOD performance of PLMs on relation extraction (RE) and machine reading comprehension (MRC) by 5.7 points and by 9.1 points, respectively. Under the black-box setting, our in-context intervention effectively reduces the entity-based knowledge conflicts of GPT-3.5, achieving up to 20.5 points of improvement of exact match accuracy on MRC and up to 17.6 points of reduction in memorization ratio on RE.
